| Using Windows Resource Language Codes for Attribution | 2014-12-23 20:25 |
Since news of the Sony hack broke, a number of reports have been pointing to North Korea as the source of the compromise. Part of the reasoning that North Korea is to blame is undoutedly because the malware recovered from the compromise, and subsequently made available on a number of malware analysis websites, had internal resources that had the Korean language. While the languages associated with Windows resources on executables can be used for attribution, this post will show that they should not be singularly relied upon.
Disclosure: KoreLogic is not involved with this investigation, nor do we have any inside knowledge. This post is based on the public information available and our experience and expertise.
What are Resources?
Resources are binary data that are attached directly to Windows programs and are used during execution. A number of standard resource types exist, including menus, icons, cursors, string tables, and version information. Programmers can also attach user-defined resources, which can be anything. Malware will often use resources to attach configuration files or secondary pieces of malware that are dropped and executed.
Each resource has a number of characteristics that are stored in the executable. These include the name of the resource, its type, its location and size within the executable, and the locale information of the resource. The locale information, which describes the geographic region the resource is meant for, includes the language and sublanguage IDs of the resource.
Language Identifiers
The language and sublanguage IDs are 16-bit numeric identifiers that describe the primary language of the resource (e.g. English, Spanish, Arabic, etc.) and the region for that language (e.g. for English: United States, United Kingdom, South Africa, etc.). In the locale information, the language values are constructed using the MAKELANGID macro, which uses the following algorithm:
LANGINFO = (SUBLANG_ID << 10) | LANG_ID
A list of all language ID values is available on MSDN.
For example, the language ID for English is 0x09 and the sublanguage ID for the U.S. is 0x01. Therefore, the language value for U.S. English is 0x0409. The language associated with a resource can be parsed out by numerous PE editing tools, and of course, MASTIFF.
 Resource information from a Zeus malware interpreted by MASTIFF.
Resource information from a Zeus malware interpreted by MASTIFF.
The ability to specify different resources based on language is helpful when supporting localization of an executable. For example, if a programmer wanted to make his program multilingual, he could add menus for English and Spanish to the executable instead of compiling two different versions of the program. Programmatically, loading resources based on language can be done with FindResource() or by enumerating all of the resources for a specific language with EnumResourceLanguages().
Most resources are added to executables during the complilation process, although this can also be performed programmatically. When resources are added to a program, the programmer specifies the language and sublanguage ID of the resource using either the LANGUAGE statement in the resource's .rc configuration file or within the compiler. If the language ID is not specified, the compiler (or at least Visual Studio) will use the language and sublanguage of the system the program is being compiled on.
Language Identifiers in Attribution
So why should analysts care about resources and their languages? If the malware author forgets to set the language of the resource, which is often the case, the compiler will use the language code of the author's system. While this won't provide the exact coordinates of the author, it will give a general geographic location and can be used for threat intelligence attribution (e.g. this malware was compiled in China, Brazil, US, etc.).
However, there is a problem with blindly using the language codes in an executable for threat intelligence. Developers can set the language code of a resource to be whatever they want it to be. Therefore, if the developer wants an analyst to think the malware came from Russia, she only needs to set the language code to LANG_RUSSIAN (0x19) and the sublanguage to Russia (0x01) (locale ID 0x0419). If she wants to make it appear the malware came from Korea, she can set the language code to LANG_KOREAN (0x12) and the sublanguage code to Korea (0x01) (locale ID 0x0412).
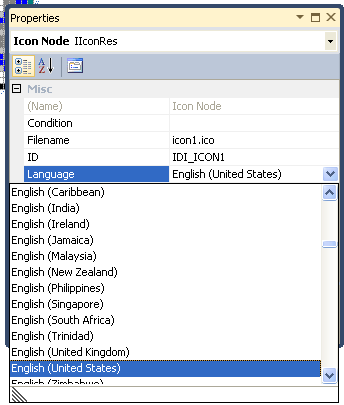
During the development process, this is often as easy as selecting the language from a drop-down box. The image on the right shows a program in Visual Studio 2012 that had an icon resource attached. Initially, the resource was given the language code English (United States) since that is the default language of my development system. However, the language could be changed to any other using the drop-down box in the VS GUI.
Analysts need to make sure that the language information is used in context with the rest of the information available on the malware. If there are other indicators that support the language IDs being real, then all the better. Examples of additional indicators include command and control IP addresses in that geographic region, internal debug or help strings in that language, and additional intelligence that is available on the attacker or malware origins. If there is not any additional supporting information, treat the language codes with a grain of salt.
Keep in mind that no checks are performed when a program is executed to determine if the language IDs have been changed, meaning an attacker could modify the language IDs of a resource after compilation. This could easily be done with a script that modifies the language code of malware resources every time it's downloaded as a means to change the malware's hashes or signature.
Using the program we created in the example above, analyzing it within MASTIFF finds that its resources have a language code of US English (0x0409).
 Resources with the US English language code.
Resources with the US English language code.
By opening the program up in a hex editor, we can change the language to another by modifying the language values. In the example below, the code is changed from US English (0x0409) to Korean (0x0412). Note, bytes are reversed because they are stored in little-endian format.
 Resource language codes manually changed in a hex editor.
Resource language codes manually changed in a hex editor.
MASTIFF, and any other PE analysis program, then shows the language for the resources as Korean.
 Previously changed resources now show the language as Korean.
Previously changed resources now show the language as Korean.
In malware analysis, it is often desirable to perform some type of attribution to determine where the malware came from. If the language codes for resources are set, then this allows analysts to get a general geographic feel for the malware's origin. However, since the language codes can be arbitrarily changed or set, they cannot be used as a singular indicator. As long as additional information is available that supports the language code as being real, then it can and should be used as an excellent intelligence resource.
References:
- MS Language IDs and Constants: http://msdn.microsoft.com/en-us/library/windows/desktop/dd318693%28v=vs.85%29.aspx
- Resource Types: http://msdn.microsoft.com/en-us/library/ms648009%28v=vs.85%29.aspx
- Menus and Other Resources: http://msdn.microsoft.com/en-us/library/windows/desktop/ms632583%28v=vs.85%29.aspx
- LANGUAGE statement: http://msdn.microsoft.com/en-us/library/windows/desktop/aa381019%28v=vs.85%29.aspx
- FindResource: http://msdn.microsoft.com/en-us/library/ms648042%28v=vs.85%29.aspx
- EnumResourceLanguages: http://msdn.microsoft.com/en-us/library/ms648035%28v=vs.85%29.aspx
- MAKELANGID: http://msdn.microsoft.com/en-us/library/windows/desktop/dd373908%28v=vs.85%29.aspx
| Posted by Tyler at: 20:25 permalink |